由于之前只接触过纯C的binary(rust看过一个,但是看不懂),对C++的binary比较陌生,此外C的汇编其实也没怎么深入学习过,一般做题都是直接F5,看不懂了才去看汇编……
正好最近ICS学到汇编语言,TA大大给我们推荐了一个C/C++的汇编讲解:从汇编角度学习C/C++ - 1900,所以决定好好学习一下!
这是第0篇笔记,主要是C的汇编,不涉及C++的面向对象特性。
数据类型
基本数据类型
关于最基本的数据类型,没什么好记的。
不过C++相比C,多了一个bool类型,就是一个单纯的byte……
浮点数比较特殊。似乎浮点数的指令集与实现各有不同。这个文章系列讲解用的是x87指令集,但是我的电脑和现在大部分amd64的机器应该都是SSE指令集?会用到xmm0等128位的寄存器(甚至在初始化结构体的时候也会用到这些寄存器)。
这个问题以后遇到了再深入研究吧,现在先挂着。
结构体
在C/C++中,结构体在栈上也是以从低到高的直观方式进行存储的,和内存当中一致。
但是值得注意的是,对于结构体的赋值操作,程序会把对应的结构体的值全部赋值过去。也就是直接复制出一个新的结构体。
这一点和Java中非常不一致,关于赋值到底是引用还是复制,一定要好好搞清楚。
字符串 & 数组
字符串是一个很有意思的东西,它既是数组又不是数组,既是指针又不是指针。为了看看字符串是如何存储的,我写了一个简单的程序:
1
2
3
4
5
6
7
| char str_global[] = "Hello";
int main()
{
char* str_local = str_global;
char* str2_local = "I'm Jacky";
char str3_local[] = "I'm Jacky";
}
|
对应的汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| str_global:
.string "Hello"
.LC0:
.string "I'm Jacky"
main:
push rbp
mov rbp, rsp
# char* str_local = str_global;
mov QWORD PTR [rbp-8], OFFSET FLAT:str_global
# char* str2_local = "I'm Jacky";
mov QWORD PTR [rbp-16], OFFSET FLAT:.LC0
# char str3_local[] = "I'm Jacky";
movabs rax, 7738135555752142665
mov QWORD PTR [rbp-26], rax
mov WORD PTR [rbp-18], 121
mov eax, 0
pop rbp
ret
|
可以看到,用数组来表示字符串和用指针来表示字符串是不一样的。主要的区别在于字符串的内容放不放在栈上。
用数组的方式来初始化一个字符串,编译器将会采用立即数赋值的方式,把这个字符串硬编码在代码部分当中,然后存到栈上。(而如果字符串很长,编译器将会把字符串字面量存在内存之中,然后使用rep movsq指令,把位于内存地址中的字面量复制到栈上)
而用指针来初始化,编译器将会将字面量存在内存中,然后直接把地址赋给对应的指针。
引用 & 指针
C++为了方便程序员,推出了“引用”的概念,用来方便程序员在函数里面修改变量&节省传递参数时耗费的空间(传值需要把整个参数都复制一遍)。
但是引用在汇编当中的表示是什么呢?
答案是……和指针完全没有任何区别!
引用和指针在内存中存储形式是一样的,引用只是编译器对指针的封装罢了。
非顺序控制流
条件跳转
首先来回顾一下CSAPP里的条件跳转指令表。
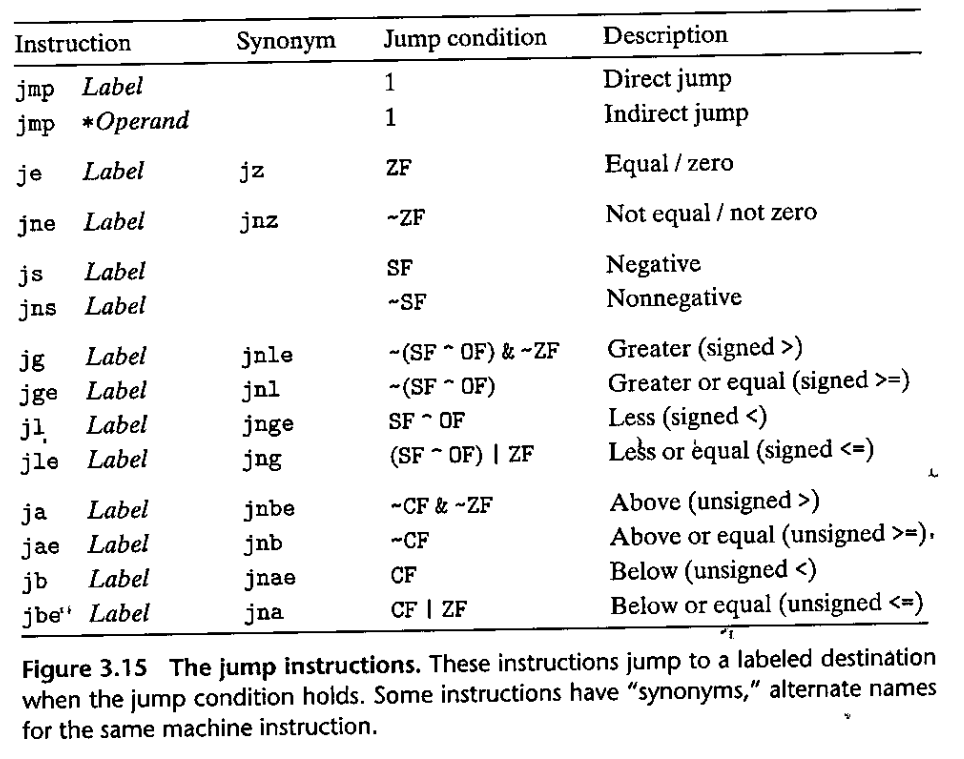
基本的条件跳转这里略过。但是有一个很有意思的地方——逻辑运算符&&和||。
逻辑运算符,直观想象一下,应该是先计算表达式的值,然后用计算好的值来进行判断;
但是实际上,这些逻辑运算符可能会被优化成实际的判断。
对于&&程序,会经过两次判断条件是否都成立,任何一次条件不成立都会导致语句块不被执行且第一次判断如果不成立就不会进行第二次判断。
而对于||,任何一次条件成立都会导致语句块被执行,且如果第一次条件成立就不会进行第二次判断,直接跳转到条件成立的语句进行执行。
考虑一下逻辑表达式的特性,就可以知道,先计算整个表达式再进行条件判断是没有办法拥有这种特性的。
也就是说,之所以采用一个表达式多次判断的方法,就是为了优化控制流的时间,让执行的指令更少,程序运行速度更快。
条件跳转 - switch
另外,switch case语句作为比较特殊的一种条件判断,被设计出来是为了优化一种特化的情况。
我将一种理想的情况展示如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| int main()
{
int a = 0;
switch (a) {
case 0:
return 0;
case 1:
return 1;
case 2:
return 2;
case 3:
return 3;
case 4:
return 4;
default:
return 5;
}
}
|
对应的汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| main:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], 0
# if (a > 4) jmp default
cmp DWORD PTR [rbp-4], 4
ja .L2
# CAUTION: directly use a as index of jmp table
mov eax, DWORD PTR [rbp-4]
mov rax, QWORD PTR .L4[0+rax*8]
jmp rax
# jmp table
.L4:
.quad .L8
.quad .L7
.quad .L6
.quad .L5
.quad .L3
.L8:
mov eax, 0
jmp .L9
.L7:
mov eax, 1
jmp .L9
.L6:
mov eax, 2
jmp .L9
.L5:
mov eax, 3
jmp .L9
.L3:
mov eax, 4
jmp .L9
.L2:
mov eax, 5
.L9:
pop rbp
ret
|
如果不在跳转表中(也就是a >= 5),就直接跳到L2,也就是default标签;
否则,就可以直接用a作为跳转表的index,整个跳转表是存在内存的某一个位置的(可能是rodata段)。
可以看到,汇编代码比起if-else语句,不论是可读性,还是从执行流的速度来讲,都大大地提升了。
但是如果没有我给出的例子那么理想,编译器会进行一些处理,来把情况再转化为比较理想的情况。比如,如果是case 35、36、……、45的情况,那么程序会首先把变量减去一个值35,然后再作为跳转表的index来使用。
循环
循环没什么特别需要注意的地方,但是有一个比较搞的地方,就是编译器会把for循环的各个部分放到不同的地方,十分反直觉……
比如这段汇编(把偏移改成人话了):
1
2
3
4
5
6
7
8
| mov DWORD PTR [i], 0
jmp .L2
.L3:
sub DWORD PTR [a], 1
add DWORD PTR [i], 1
.L2:
cmp DWORD PTR [i], 4
jle .L3
|
可以看到前两行属于是整个循环的初始化,L3是循环体和i++,L2是循环条件判断。
所以这个顺序和C语言当中这个循环的样子完全不一样……
过程调用(函数)
由于学了半年pwn了,函数的调用过程已经很熟了(悲)。
但是还是有一些可以学习的地方,比如——结构体参数如何传递。
结构体作为参数传递的时候,程序会开辟出一段空间来存储这个变量并且会压入一个地址作为参数
而后程序将这个地址作为返回值返回给主函数,主函数根据这个地址将结构体的内容赋值到我们需要的变量中。
自己研究结构体调用的汇编代码后,发现子函数的局部变量test_ret并不是存在它自己的函数栈帧当中,而是存在main函数的函数栈帧当中的……
main函数调用子函数时,会把栈顶地址压入rdi,让子函数把返回值填进去;然后另开辟一块空间用来传递实参……
这个优化比较神奇,所以我把代码贴一下,方便理解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#include <cstdio>
#include <cstring>
#pragma pack(1)
typedef struct _Test
{
char cTest;
int iTest;
char arrTest[11];
} Test;
Test structTest(Test test)
{
Test test_ret = { 0 };
test_ret.cTest = test.cTest;
test_ret.iTest = test.iTest;
strcpy(test_ret.arrTest, test.arrTest);
return test_ret;
}
int main()
{
Test test1 = { 0 }, test2 = { 0 };
test1.cTest = 'a';
test1.iTest = 1900;
strcpy(test1.arrTest, "Hello 1900");
test2 = structTest(test1);
return 0;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| structTest(_Test):
push rbp
mov rbp, rsp
sub rsp, 16
mov QWORD PTR [rbp-8], rdi
mov rax, QWORD PTR [rbp-8]
pxor xmm0, xmm0
movups XMMWORD PTR [rax], xmm0
movzx edx, BYTE PTR [rbp+16] # 函数不通过rdi获取实参,而是直接用rbp+16
mov rax, QWORD PTR [rbp-8]
mov BYTE PTR [rax], dl
mov edx, DWORD PTR [rbp+17]
mov rax, QWORD PTR [rbp-8]
mov DWORD PTR [rax+1], edx
lea rax, [rbp+21]
mov rdx, QWORD PTR [rbp-8]
add rdx, 5
mov rsi, rax
mov rdi, rdx
call strcpy
nop
mov rax, QWORD PTR [rbp-8] # 返回值地址是开始时rdi传进来的那个地址
leave
ret
main:
push rbp
mov rbp, rsp
sub rsp, 48
pxor xmm0, xmm0
movaps XMMWORD PTR [rbp-16], xmm0
pxor xmm0, xmm0
movaps XMMWORD PTR [rbp-32], xmm0
mov BYTE PTR [rbp-16], 97
mov DWORD PTR [rbp-15], 1900
movabs rax, 4121110796953216328
mov QWORD PTR [rbp-11], rax
mov DWORD PTR [rbp-4], 3158073
# 开始准备调用
lea rcx, [rbp-48]
sub rsp, 16 # 新开一块空间存储实参
mov rsi, rsp
mov rax, QWORD PTR [rbp-16] # 把实参复制过去
mov rdx, QWORD PTR [rbp-8]
mov QWORD PTR [rsi], rax
mov QWORD PTR [rsi+8], rdx
mov rdi, rcx # 然而rdi存的是实参结构上面的地址[rbp-48]
call structTest(_Test)
add rsp, 16
mov rax, QWORD PTR [rbp-48]
mov rdx, QWORD PTR [rbp-40]
mov QWORD PTR [rbp-32], rax
mov QWORD PTR [rbp-24], rdx
mov eax, 0
leave
ret
|
编译器,很神奇吧。